
Real-time free-viewpoint rendering requires balancing multi-camera redundancy with the latency constraints of interactive applications. We address this challenge by combining lightweight geometry with learning and propose 3DTV, a feedforward network for real-time sparse-view interpolation. A Delaunay-based triplet selection ensures angular coverage for each target view. Building on this, we introduce a pose-aware depth module that estimates a coarse-to-fine depth pyramid, enabling efficient feature reprojection and occlusion-aware blending. Unlike methods that require scene-specific optimization, 3DTV runs feedforward without retraining, making it practical for AR/VR, telepresence, and interactive applications. Our experiments on challenging multi-view video datasets demonstrate that 3DTV consistently achieves a strong balance of quality and efficiency, outperforming recent real-time novel-view baselines. Crucially, 3DTV avoids explicit proxies, enabling robust rendering across diverse scenes. This makes it a practical solution for low-latency multi-view streaming and interactive rendering.
To synthesize a query viewpoint $\mathbf{q}$, we select a sparse set of three supporting input cameras. While standard $k$-Nearest Neighbor selection often yields poorly conditioned configurations, we propose a projection-based strategy leveraging 2D Delaunay triangulation to ensure the query is spatially bracketed by its neighbors.
For inward-facing setups, we fit a cylinder to the camera centers and perform a two-stage projection: Radial Normalization to remove depth bias, followed by Perspective Mapping onto a projection plane. After computing the triangulation $\mathcal{T}$, we identify the enclosing triangle via the Müller-Trumbore ray intersection algorithm, ensuring the selected triplet provides an enclosing view coverage.
To satisfy real-time constraints, we utilize a hierarchical backbone built upon GhostNetV2. Each block uses a Ghost module where a subset of feature maps is produced via standard convolution, while the remaining channels are generated through inexpensive depthwise operations. This significantly reduces redundancy without sacrificing representational capacity.
The backbone generates a seven-level feature pyramid $\{\mathcal{F}_i^l\}_{l=0}^{6}$. To compensate for spatial detail loss in deeper layers, we append a Lightweight Atrous Spatial Pyramid Pooling (L-ASPP) module at the coarsest level. This module aggregates multi-scale context through distinct dilation rates, enriching the representation with global information while maintaining a low computational footprint.
We estimate dense depth maps for the novel view using a recursive plane-sweep stereo formulation. At the coarsest level, we initialize 32 depth hypotheses uniformly. For finer levels, the search space is refined using a local window around the upsampled prediction from the previous stage: $\mathcal{D}^l = \{ D^{l+1}_{\uparrow} + \delta \}$.
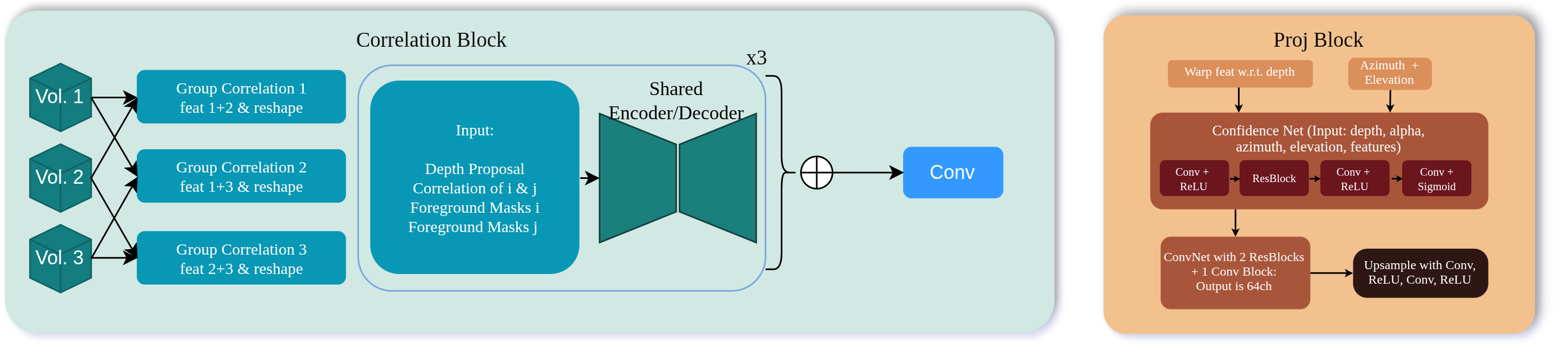
To preserve matching cues, we construct grouped correlation volumes. Feature channels are partitioned into $G$ groups, and group-wise correlations are computed at each depth hypothesis. This volume is processed alongside warped foreground masks and upscaled latents $Z^{l+1}$ from the feature projector which acts as a guiding self-prior. A shared decoder then regresses a depth residual $\Delta^l$ and an opacity map $A^l$, allowing for sub-pixel accuracy through iterative updates.
The final stage warps source features into the target frame using the estimated depth $D^l$. To account for occlusions and view-dependent effects, a confidence prediction network generates per-pixel weights $W_i^l$ based on the warped features and geometric metadata (azimuth and elevation).
Image synthesis is performed by a strictly hierarchical decoder. At each level, the fused features are combined with the refined depth, opacity maps, and upsampled latents from coarser levels. This formulation ensures that global structures estimated at low resolutions effectively regularize high-frequency detail synthesis at finer scales. The final latent $Z^0$ is then mapped to the RGB output $I_{\text{novel}}$ via a lightweight refinement head.
3DTV is able to recover flickering and projection ambiguities that arise when using 2-camera setups by using 3 cameras. While it still lacks the high fidelity of methods that use all available cameras for reconstruction it is able to mimic the stability at a fraction of the computational cost and runs in real-time. In turn it produces slightly more blurry results and removes objects from a novel view too soon if objects start to stack behind one another in the target view but are not yet fully covered by the foremost subject.
For more results please check the paper. More videos will be added soon!
| Method | 1024 $\times$ 1024 | 2048 $\times$ 2048 | ||||
|---|---|---|---|---|---|---|
| Mem. $\downarrow$ | Train $\downarrow$ | Inference $\downarrow$ | Mem. $\downarrow$ | Train $\downarrow$ | Inference $\downarrow$ | |
| Nerfacto-big* (x) | 12.1 GB | 100.3 min | 7.8 ms | 12.8 GB | 108.3 min | 9.6 ms |
| Splatfacto-big* (x) | 1.2 GB | 11.2 min | 1.3 ms | 2.6 GB | 13.1 min | 1.8 ms |
| FrugalNeRF* (3) | 20.2 GB | 12.3 min | 13.2 ms | 20.4 GB | 16.2 min | 16.5 ms |
| ENeRF (3) | 8.1 GB | 0 ms | 97.3 ms | 13.1 GB | 0 ms | 233.7 ms |
| GPS-Gaussian (2) | 3.2 GB | 0 ms | 73.7 ms | 8.1 GB | 0 ms | 119.2 ms |
| GPS-Gaussian+ (2) | 3.4 GB | 0 ms | 72.4 ms | 8.2 GB | 0 ms | 154.9 ms |
| RIFTCast (x) | 5.7 GB | 0 ms | 47.3 ms | 6.2 GB | 0 ms | 50.7 ms |
| Ours (3) | 7.1 GB | 0 ms | 117.1 ms | 20.6 GB | 0 ms | 542.7 ms |
| 3DTV (OursRT) (3) | 2.2 GB | 0 ms | 24.5 ms | 8.0 GB | 0 ms | 109.5 ms |
Memory and speed comparisons conducted on a single NVIDIA RTX 4090 GPU. * denotes optimization-based methods requiring per-scene training. (x) indicates how many views each method is using per step with x indicating using all available views. OursRT denotes our TensorRT-optimized deployment.
misc{schulz20263dtvfeedforwardinterpolationnetwork,
title={3DTV: A Feedforward Interpolation Network for Real-Time View Synthesis},
author={Stefan Schulz and Fernando Edelstein and Hannah Dröge and Matthias B. Hullin and Markus Plack},
year={2026},
eprint={2604.11211},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.11211},
}